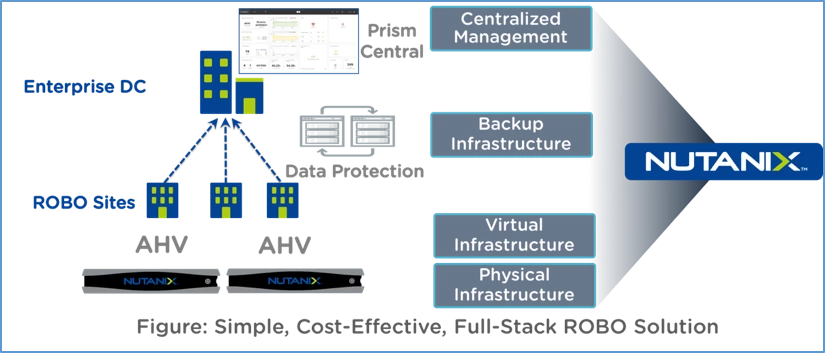
Table Content
- Introduction
- Two-Node Cluster Features
- Unsupported features
- Two-Node Cluster Guidelines
- Witness VM considerations
- 2-Node Cluster Supported Hardware (Nutanix NX models)
- 2-Node Cluster Supported Hardware (DX models)
- Failure and Recovery Scenarios
- Remote and Branch Office (ROBO) Per Virtual Machine License
Introduction
A traditional Nutanix cluster requires a minimum of three nodes, but Nutanix also offers the option of a two-node cluster for ROBO implementations and other situations that require a lower cost yet high resiliency option.
A two-node cluster can still provide many of the resiliency features of a three-node cluster. This is possible by adding an external Witness VM in a separate failure domain to the configuration.
Two-Node Cluster Features:
- Replication factor (RF)
- RF2 spanned over two nodes and RF4 for metadata on SSDs over two nodes. RF4 for metadata helps during a node failure scenario to quickly transition the healthy node to run in single-node mode with the metadata remaining disk fault tolerant. (Metadata in a two-node cluster is typically small, so the storage need for four copies is modest.)
- Single node failure effects
- 50% resource loss. Plan for 40% maximum resource usage to avoid read-only state on the remaining node. Data is made RF2 in the background so that data is resilient.
- Drive failure effects
- one node + one SSD failure (on other node) = read-only mode.
- Hypervisors supported
- AHV and ESXi
- Compression
- Asynchronous DR
Unsupported features:
- Cluster expansion
- Dedupe
- Erasure coding
- Near sync DR and Metro Availability
- Network segmentation
Two-Node Cluster Guidelines:
- Size your implementation for N + 1 so that in the event of a node loss (50% loss of resources) the remaining node will have sufficient resources to allow the cluster to continue functioning.
- The upgrade process in a two-node cluster may take longer than the usual process because of the additional step of syncing data while transitioning between single and two node state. Nevertheless, the cluster remains operational during upgrade.
Witness VM considerations:
- A Witness VM for two-node clusters requires a minimum of 2 vCPUs, 6 GBs of memory, and 25 GBs of storage.
- The same Witness VM can be used for both Metro Availability and two-node clusters, and a single Witness VM can support up to 100 instances (any combination of two-node clusters and Metro Availability protection domains).
- You can bring up a two-node cluster without a Witness VM being present initially, but it is recommended that the Witness VM be alive and running before starting the cluster.
- The Witness VM may reside on any supported hypervisor, and it can run on either Nutanix or non-Nutanix hardware, except AWS and Azure cloud platforms.
- Network latency between a two-node cluster and the Witness VM should not exceed 500 ms.
- Node removal is not supported, but node replacement is supported
- All node maintenance work flows (software upgrades, life cycle manager procedures, node and disk break-fix procedures, boot drive break-fix procedure) require that the cluster be registered with a Witness VM.
2-Node Cluster Supported Hardware (Nutanix NX models):
NX-1175S-G8
NX-1120S-G7
NX-1175S-G7
2-Node Cluster Supported Hardware (DX models):
DX360 Gen10 4LFF
DX360 Gen10 Plus 4LFF
Failure and Recovery Scenarios:
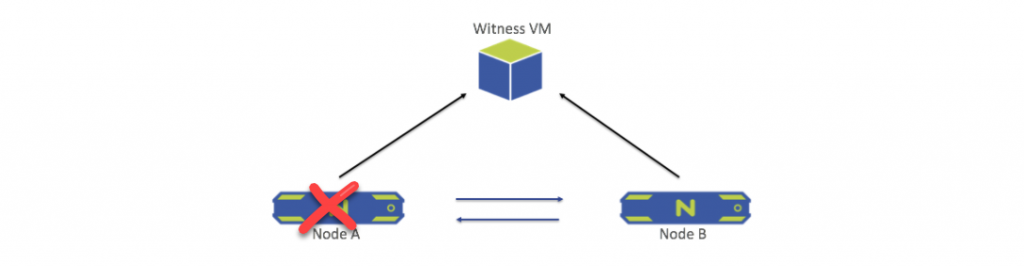
Node Failure
When a node goes down, the live node sends a leadership request to the Witness VM and goes into single-node mode. In this mode RF2 is still retained at the disk level, meaning data is copied to two disks. (Normally, RF2 is maintained at the node level normally meaning data is copied to each node.) If one of the two metadata SSDs fails while in single-node mode, the cluster (node) goes into read-only mode until a new SSD is picked for metadata service. When the node that was down is back up and stable again, the system automatically returns to the previous state (RF2 at the node level). No user intervention is necessary during this transition.
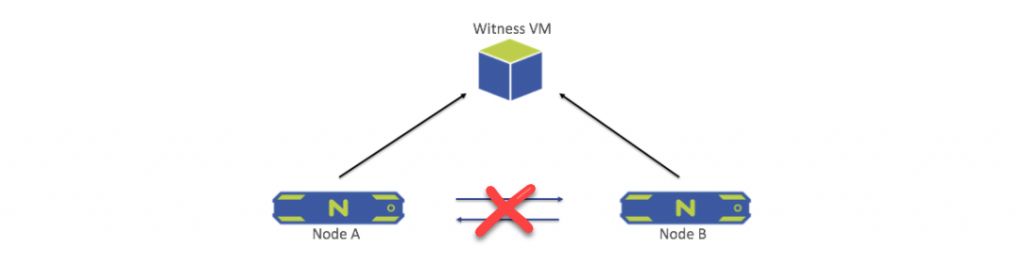
Network Failure Between The Nodes
When the network connection between the nodes fails, both nodes send a leadership request to the Witness VM. Whichever node gets the leadership lock stays active and goes into single-node mode. All operations and services on the other node are shut down, and the node goes into a waiting state. When the connection is re-established, the same recovery process as in the node failure scenario begins.
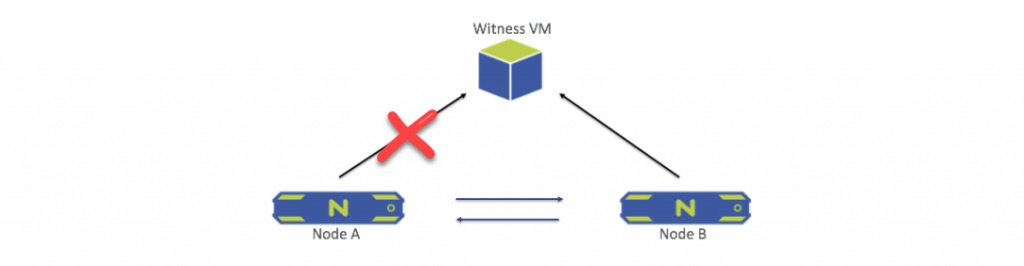
Network Failure Between Node and Witness VM
When the network connection between a single node (Node A in this example) and the Witness fails, an alert is generated that Node A is not able to reach the Witness. The cluster is otherwise unaffected, and no administrator intervention is required.
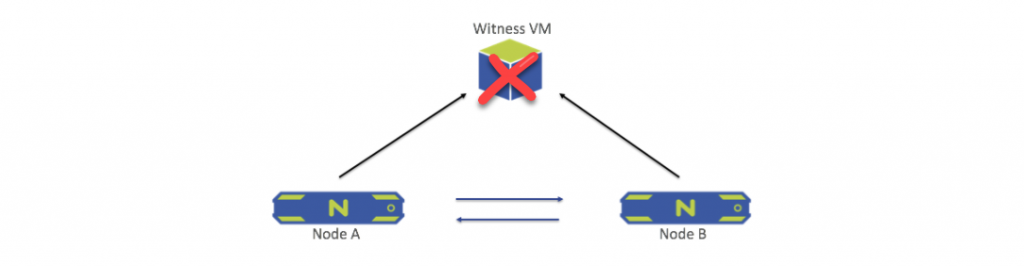
Witness VM Failure
When the Witness goes down (or the network connections to both nodes and the Witness fail), an alert is generated but the cluster is otherwise unaffected. When connection to the Witness is re-established, the Witness process resumes automatically. No administrator intervention is required.
If the Witness VM goes down permanently (unrecoverable), follow the steps for configuring a new Witness through the Configure Witness option of the Prism web console.
Remote and Branch Office (ROBO) Per Virtual Machine License
The ROBO per VM model combines AOS, AHV and Prism together with pricing on a per VM basis. This licensing model is an alternative to capacity-based and appliance licensing and is designed for sites running typically up to 10 VMs.
- Term license: 1 through 5-year options
- Must run on a dedicated ROBO cluster with no capacity-based licensing
- Available in AOS Pro and Ultimate editions

Presales Consultant with more than 10 years of experience, supports our partners by understanding customer needs, presenting and demonstrating our vendors’ products and helping in deal closing.